个人练习


# coding=utf-8import re# print(re.findall("a..x","asdfdaesx")) # . 通配符# print(re.findall('^a..x',"asdfdaesx")) # ^ 只能在字符串的开头匹配内容# print(re.findall('^a..x$',"asdfdaesx")) # $ 作为结尾匹配的# print(re.findall('a..x$',"asdfdaesarrx")) # $ 作为结尾匹配的# 重复符号 * + ? {}# print(re.findall('alex*',"asdfsdfalexxx")) # * 0到无穷次# print(re.findall('alex*',"asdfsdfale")) # * 0到无穷次 匹配方式:贪婪匹配# print(re.findall('alex+',"asdfsdfalexxx")) # + 1到无穷次 匹配方式:贪婪匹配# print(re.findall('alex+',"asdfsdfale")) # + 1到无穷次# 把贪婪匹配改成惰性匹配,在后面加?# ret=re.findall('abc*?','abcccccc')# print(ret) # ['ab']# ?匹配【0,1】# print(re.findall('alex?',"asdfsdfalexxx")) #? 只能匹配0个或者1个 匹配方式:贪婪匹配# print(re.findall('alex?',"asdfsdfale")) #? 只能匹配0个或者1个# {} 要取多少就取多少# {0,}==*# {1,}==+# {0,1}==?# {6} ==6次# {0,6}==0到6次# print(re.findall('alex{6}',"asdfsdfalexxx"))# print(re.findall('alex{0,6}',"asdfsdfalexxx"))# print(re.findall('alex{0,1}',"asdfsdfalexxx"))# 元字符之字符集[]:没有特殊符号# print(re.findall('x[yz]','xyuuuuxzuu'))# print(re.findall('x[yz]p','xypuuuuxzpuu'))# print(re.findall('x[y,z]p','xypuuuuxzpux,pu'))# print(re.findall('q[a*z]','sdfsqaa'))# print(re.findall('q[a*z]','sdfsq*'))# print(re.findall('q[a-z]','quos')) # 只是取a到z其中的一个# print(re.findall('q[a-z]*','quos')) # 字符集重复# print(re.findall('q[a-z]*','quossdfsdf9')) # 9不符合a到z的条件,所以不会出现# print(re.findall('q[0-9]*','quossdfsdf9'))# print(re.findall('q[0-9]*','q888uossdfsdf9'))# print(re.findall('q[0-9]*','q888uossdfsdfq9'))# print(re.findall('q[A-Z]*','q888uossdfsdfq9'))# print(re.findall('q[^a-z]','q888uossdfsdfq9')) # 匹配不是a到z的 ‘非’# #在字符集里有功能的符号: - ^ \,其他的都是正常的符号# print(eval("12+(34*6+2-5*(2-1))"))# print(re.findall("\([^()]*\)","12+(34*6+2-5*(2-1))"))# \d 匹配任何十进制数;它相当于类 [0-9]。# print(re.findall('\d','12+(34*6+2-5*(2-1))'))# print(re.findall('\d+','12+(34*6+2-5*(2-1))'))# \D 匹配任何非数字字符;它相当于类 [^0-9]。# print(re.findall('\D+','12+(34*6+2-5*(2-1))'))# \s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。# print(re.findall('\s+','hello world'))# print(re.findall('\S+','hello world'))# print(re.findall('\w','hello world'))# print(re.findall('\W','hello world'))# print(re.findall('www.baidu','www.baidu'))# print(re.findall('www\.baidu','www/baidu'))# print(re.findall('www\.baidu','www.baidu'))# print(re.findall('www*baidu','www*baidu'))# print(re.findall('www\*baidu','www*baidu'))
模块(modue)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突
time模块(* * * *)
三种时间表示
在Python中,通常有这几种方式来表示时间:
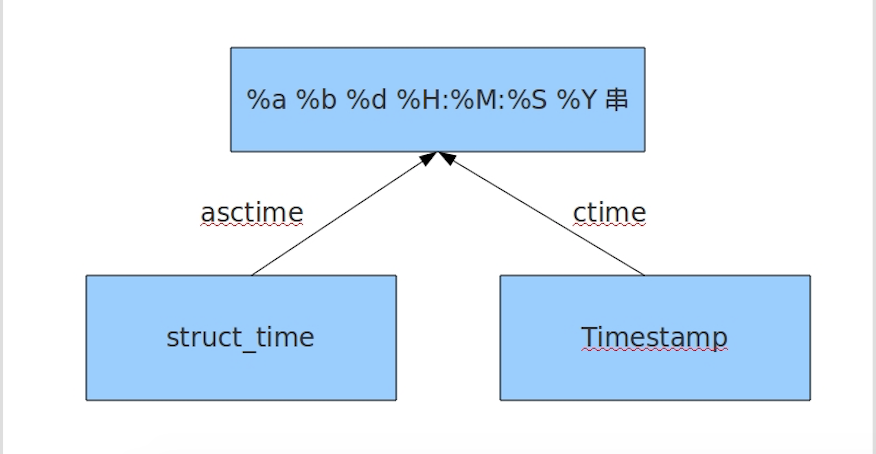
- 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串
- 元组(struct_time) : struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
time时间模块
import time# 时间戳# print(time.time()) #1970年到现在有多少秒,做计算使用# 结构化时间# a = time.localtime()# print(a)# print(a.tm_year)# print(a.tm_wday) #从零开始数,表示周几# print(time.gmtime()) #世界标椎时间# print(time.localtime(1236543321)) # 把时间戳转化成了结构化时间# 将结构化时间转化成时间戳# print(time.mktime(time.localtime()))# 将结构化时间转换成字符串时间# print(time.strftime('%Y-%m-%d %X' ,time.localtime())) # X表示时分秒# 将字符串时间转化成结构化时间# print(time.strptime('2019:6:18:7:38:24','%Y:%m:%d:%X'))print(time.asctime()) # 将一个结构化时间转换成一个固定的字符串时间print(time.ctime()) # 将一个时间戳转换成一个固定的字符串时间 更直观 import datetime print(datetime.datetime.now())

random模块(* *)
print(random.random())#(0,1)----float
print(random.randint(1,3)) #[1,3]
print(random.randrange(1,3)) #[1,3)
print(random.choice([1,'23',[4,5]]))#23
print(random.sample([1,'23',[4,5]],2))#[[4, 5], '23']
print(random.uniform(1,3))#1.927109612082716
item = [ 1 , 3 , 5 , 7 , 9 ] random.shuffle(item)
print(item)
验证码
def v_code(): ret=""
for i in range(5): num = random.randint(0,9) alf = chr(random.randint(65,122)) s =str(random.choice([num,alf])) ret+=s return ret
os模块(* * * *)
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cdos.curdir 返回当前目录: ('.')os.pardir 获取当前目录的父目录字符串名:('..')os.makedirs('dirname1/dirname2') 可生成多层递归目录os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirnameos.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirnameos.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印os.remove() 删除一个文件os.rename("oldname","newname") 重命名文件/目录os.stat('path/filename') 获取文件/目录信息os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'os.system("bash command") 运行shell命令,直接显示os.environ 获取系统环境变量os.path.abspath(path) 返回path规范化的绝对路径os.path.split(path) 将path分割成目录和文件名二元组返回os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素os.path.exists(path) 如果path存在,返回True;如果path不存在,返回Falseos.path.isabs(path) 如果path是绝对路径,返回Trueos.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回Falseos.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回Falseos.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 sys模块(* * *)
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit( 0 ) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的 Int 值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 进度条:
import sys,timefor i in range(10): sys.stdout.write('#') time.sleep(1) sys.stdout.flush(
json & pickle(* * * *)
json(做数据交换使用)
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
xml模块(* *)
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
2 2008 141100 5 2011 59900 xml数据 69 2011 13600
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml")root = tree.getroot()print(root.tag) #遍历xml文档for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点for node in root.iter('year'): print(node.tag,node.text)#---------------------------------------import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml")root = tree.getroot() #修改for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除nodefor country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml') 自己创建xml文档:
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist")name = ET.SubElement(new_xml,"name",attrib={ "enrolled":"yes"})age = ET.SubElement(name,"age",attrib={ "checked":"no"})sex = ET.SubElement(name,"sex")sex.text = '33'name2 = ET.SubElement(new_xml,"name",attrib={ "enrolled":"no"})age = ET.SubElement(name2,"age")age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式
re模块(* * * * *) (day22最后一集)
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('alvin','yuanaleSxalexwupeiqi') ['alvin']2 元字符:. ^ $ * + ? { } [ ] | ( ) \
元字符之. ^ $ * + ? { }
import re
ret = re.findall( 'a..in' , 'helloalvin' ) print (ret) #['alvin'] ret = re.findall( '^a...n' , 'alvinhelloawwwn' ) print (ret) #['alvin'] ret = re.findall( 'a...n$' , 'alvinhelloawwwn' ) print (ret) #['awwwn'] ret = re.findall( 'a...n$' , 'alvinhelloawwwn' ) print (ret) #['awwwn'] ret = re.findall( 'abc*' , 'abcccc' ) #贪婪匹配[0,+oo] print (ret) #['abcccc'] ret = re.findall( 'abc+' , 'abccc' ) #[1,+oo] print (ret) #['abccc'] ret = re.findall( 'abc?' , 'abccc' ) #[0,1] print (ret) #['abc'] ret = re.findall( 'abc{1,4}' , 'abccc' ) print (ret) #['abccc'] 贪婪匹配 ret = re.findall( 'abc*?' , 'abcccccc' ) print (ret) #['ab'] 元字符之字符集[]:
#--------------------------------------------字符集[]
ret = re.findall( 'a[bc]d' , 'acd' ) print (ret) #['acd'] ret = re.findall( '[a-z]' , 'acd' ) print (ret) #['a', 'c', 'd'] ret = re.findall( '[.*+]' , 'a.cd+' ) print (ret) #['.', '+'] #在字符集里有功能的符号: - ^ \,其他的符号都是正常符号 ret = re.findall( '[1-9]' , '45dha3' ) print (ret) #['4', '5', '3'] ret = re.findall( '[^ab]' , '45bdha3' ) print (ret) #['4', '5', 'd', 'h', '3'] ret = re.findall( '[\d]' , '45bdha3' ) print (ret) #['4', '5', '3'] 元字符之转义符\
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]\b 匹配一个特殊字符边界,比如空格 ,&,#等ret=re.findall('I\b','I am LIST')
print (ret) #[] ret = re.findall(r 'I\b' , 'I am LIST' ) print (ret) #['I']